 Multiverse of Minhness
Multiverse of MinhnessContents
Introduction
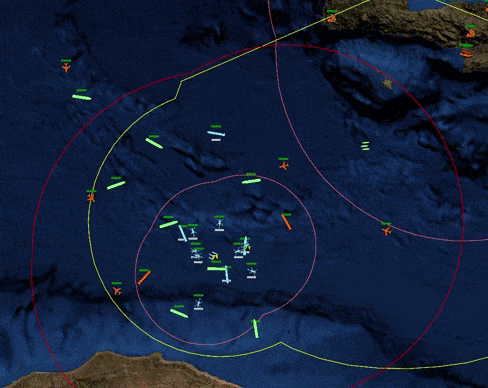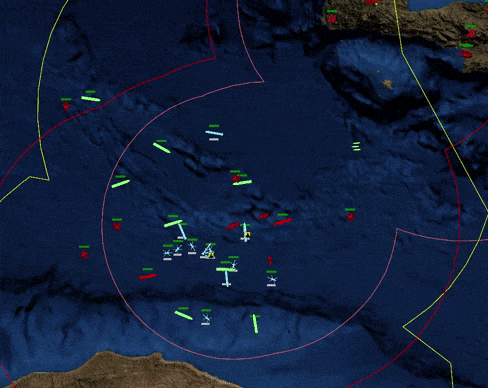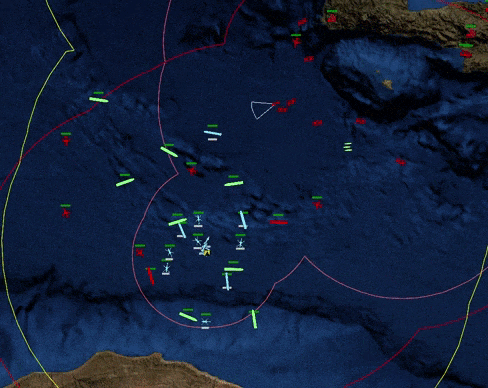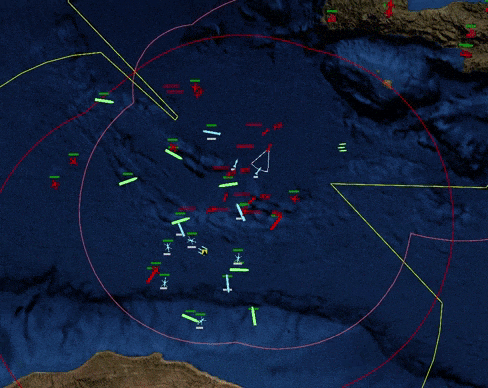
This blog post chronicles the development of PyCMO, a reinforcement learning environment for Command: Modern Operations (CMO), a warfare simulation video game that simulates military engagements and all-domain operations at the tactical level (see Figure 1). This post serves as a record of my design choices and documents my thoughts for the project's future. Although this blog post was published in February 2023, most of the work took place around August 2021. The only reason I am publishing this so late is because I have been busy with graduate school for most of 2022 (I graduated!). More on my work during that time will come in subsequent blog posts.
On August 2021, in partnership with the Air Force Research Laboratory (AFRL) Information Directorate, the National Security Innovation Network (NSIN) hosted a competition that challenged contestants to develop an artificial intelligence (AI) agent capable of autonomously playing CMO. In particular, the agents were judged on their ability to complete the scenario objectives, completion time, and expenditures. The judges also evaluated the novelty and generalizability of each approach.
At the time, there were several motivations that galvanized me to enter the competition. First, I was familiar with CMO from work, and I had experience developing software for CMO. For example, I had already developed a GUI to automatically generate scenario files (.scen) for design of experiments (DOE) studies, and a GUI to filter and process output data. Second, I was aware of AlphaStar, a reinforcement learning agent that bested human players in the real-time strategy game StarCraft II, and I thought that most of the same that DeepMind had accomplished in StarCraft II (SC2) with AlphaStar could be replicated in CMO given the similarities between the two video games. The gameplay loop in both entails the movement and tasking of units to achieve objectives against opponents. Finally, my experience conducting undergraduate research on language models gave me just enough knowledge and confidence to tackle reinforcement learning (RL), a machine learning (ML) area that I had not yet explored.
The preparation phase consisted of learning about AlphaStar and how the software interacted with the game; my goal was to build a version of AlphaStar compatible with CMO. Preliminary research revealed that this work would need to proceed in two phases. Whereas AlphaStar represents the game-playing agent, the environment is managed by a separate DeepMind project, the StarCraft II Learning Environment (SC2LE), and the repository is hereafter referred to as PySC2. PySC2 is a Python RL environment built around SC2 and manages the exchange of observations, actions, and rewards between the game and the agent. At this point, given the limited competition time and my one-person team's manpower, I decided to pivot my project. I prioritized the development of a reinforcement learning environment around CMO (which did not exist at the time) and left the development of the agent as a possibility only if time permits. Even if I did not get to building the agent (spoiler alert: I did not and still have not), an environment for CMO that can provide a level of abstraction akin to an OpenAI Gym environment would be immensely helpful to the research community writ large.
Background
Reinforcement Learning Environments
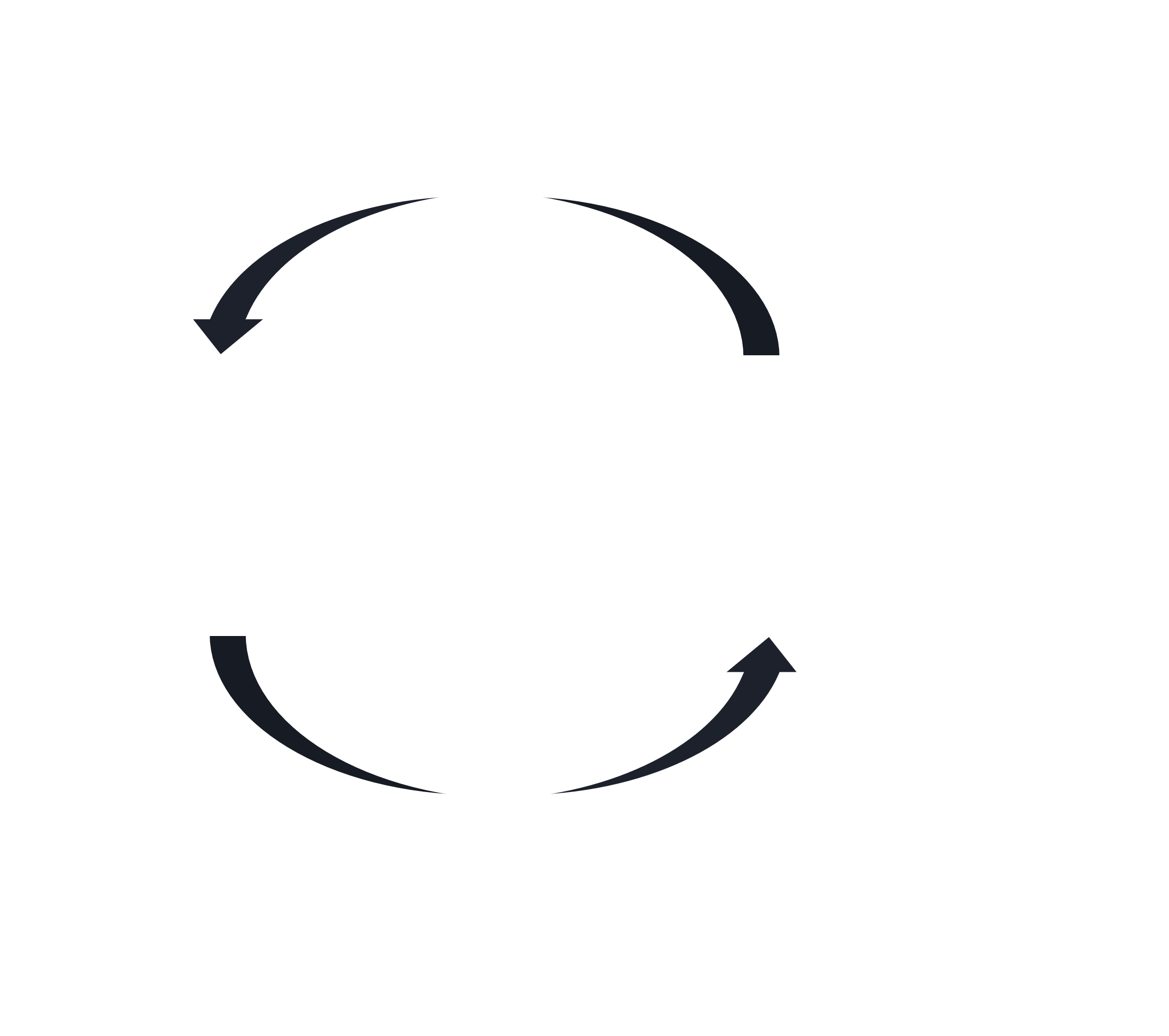
The environment is an integral part of the RL loop and can be represented by a set of states, where at each timestep, the environment is in a particular state (see Figure 2). The agent interacts with the environment by performing some action, e.g. specifying the direction to move a car on a grid, directing units to attack an objective, etc. The environment processes the action and updates its state. For example, consider a 1x2 grid with a car located at the (1, 1) cell. An agent might elect to move the car to the right, and if this action is successful, the next state sees the car located at cell (1, 2). Then, the environment returns a signal comprised of the state resulting from the agent's action (called an observation) and a reward. The reward is essential to the learning process and incentivizes the agent to take favorable actions that move it closer to the goal. For example, consider the problem of training an agent to navigate through a maze. If we assigned a negative reward for each move the agent took that did not lead to the goal and a zero or positive reward for any move that makes the agent solve the maze, we have incentivized the agent to learn to solve the maze in the least number of steps.
The good news with developing a warfare RL environment is that the simulation has already been built. CMO handles all the calculations like aircraft physics and missile endgames. The only thing I needed to do was extract and package the state information into a standard format, and to search for a mechanism that the agents can use to send actions to the environment. This initially sounded easy, but I discovered many challenges as the development proceeded. Although the environment is working as intended as of this writing, there are still many limitations to my approach.
PySC2
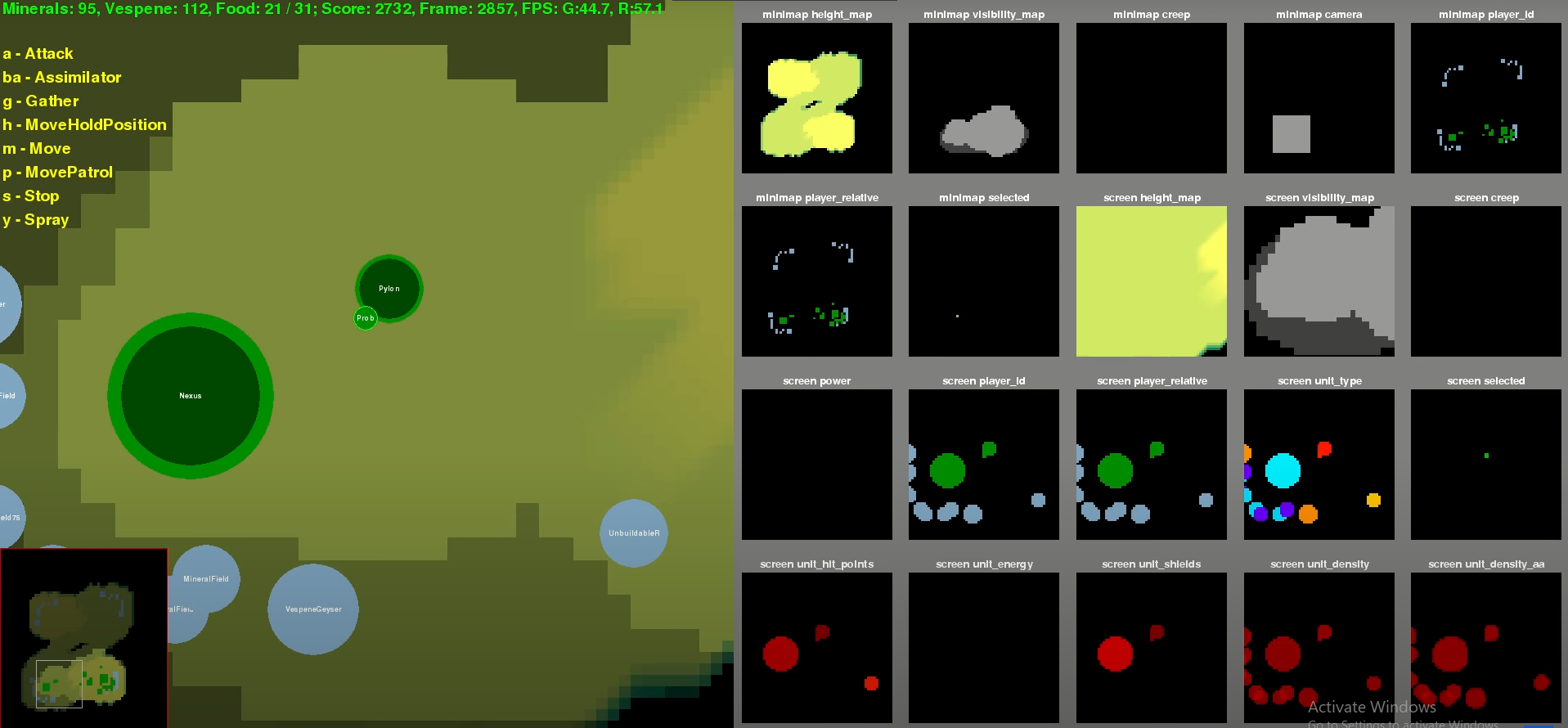
There are several key PySC2 elements that I incorporated into PyCMO. PySC2 relies on the SC2 API, which provides access to in-game state observation and unit control (see Figure 3). Observations are available in a wide variety of formats or "layers" including RGB pixels and structured data. PySC2's feature.py renders the feature layers from the SC2 API into numpy arrays, which are used by the agents. Modern deep learning agents that can play video games like Atari are trained on pixel data, which makes that layer the most attractive. However, it is currently not possible to extract pixel data from CMO. Then, the next most natural format for observations is structured data, which are tensors of features that observe some aspect of the game. For example, the single select tensor in SC2 displays information like the unit type, health, shields, and energy for the currently selected unit. This type of data is appropriate for CMO for two reasons. First, CMO structures their data in a similar format and provides access to it through their Lua API. For example, one can call a function like ScenEdit_GetUnit to get structured data for a specific unit. The second and more important reason is that structured data is all we have in CMO, unless the developers add support for more output layers, or someone develops a tool that can extract RGB pixels from CMO.
In the PySC2 documentation, the developers rightfully observed that the SC2 action space is immense with billions of possible actions. As a result, they created a set of functions that encapsulate basic and generic actions. These functions can be composed to express more complex actions, and they provide a standard format for agents to specify actions. In this sense, taking an action is the same as executing a function call within PySC2. This design also allows for the specification of actions that are only valid for certain observations. For example, one would not expect to be able to select a unit that one does not possess or is not visible. The action space is hard-coded, and the developers initially limited the available actions to actions that human players have taken. New actions would need to be added to actions.py.
This design is applicable to CMO because CMO allows for game control through its Lua API. For example, one can call ScenEdit_AttackContact and pass the attacker, the contact, and several options (e.g. type of attack and weapon allocation) to direct a unit to attack an enemy contact. Thus, we can emulate PySC2's design by creating functions that encapsulate CMO actions and providing a standard format for agents to take an action. The challenge is to identify the applicable actions that should be included in the action space. Certain essential actions such as moving a unit do not have a corresponding Lua function call. In fact, the standard way to move a unit is to update its course by calling the ScenEdit_SetUnit. In these cases, creating function "wrappers" for possible actions becomes even more important.
PyCMO
Protocol
To send data (in the form of Lua scripts) to the game from an external location, we rely on the TCP/IP feature of the professional edition of CMO. This is a severe limitation of the project because a professional license costs around $20,000 a year, and without the TCP/IP feature, agents have no way to send actions to the game. We will proceed with the assumption that we have access to a professional version of the game. protocol.py manages the communication between an agent and the game through a client-server model. The game acts as the server and receives and executes inputs (Lua scripts) from the client. The client is managed by the PyCMO environment. The agent decides on an action and directs the PyCMO environment to execute the action. The PyCMO environment then formats the action into the correct Lua script and uses the client to send the command to the game server.
In the game's configuration file (CPE.ini), we must enable the game to listen to input (AllowIO=1). Then, there are two ways to initialize a server instance. First, we can simply launch the game through the executable and open a scenario. Note that it is important to launch scenarios in edit mode because we can only run Lua scripts in this mode. Once the scenario is opened, the game will start to listen for TCP/IP inputs (the default port is 7777). Initializing the server this way is helpful for visualization purposes. However, if our intentions are to train an RL agent, then it is more appropriate to launch the game as a command line interface (CLI) instance. The Server class within protocol.py is a wrapper for a CLI instance of CMO running a specific scenario. The function Server::start_game executes a command line statement that launches an instance of the game with a scenario in CLI mode. The scenario is initially paused and the game listens for TCP/IP inputs. We can call Server::restart to start a new instance of the scenario. Thus, any RL training loop would have to rely on Server.
The Client class in protocol.py relies on the socket module to connect and send data to the Server via a TCP/IP port. The most important function is Client::send, which sends data to the game's Lua API. The function does not perform any formatting of the data before sending, so outbound data must be correctly formatted before being passed to Client::send (this is taken care of by the environment, as we will detail later). When we send data, it is important to choose an encoding as there are different types that the TCP socket will accept. The type needs to be specified in the CPE.ini configuration file.
Observations
At this point, we can pivot the discussion into the all-important topic of how CMO manages to extract observations from the game. There are three mechanisms that I know of that can be used to somewhat reliably output data from the game. First, one could set up a regular time trigger that uses the Lua io module to write observations to a local file. This approach is not preferable because we would need to write Lua scripts that specify the features we want to export, and this could change from scenario to scenario. This can become time-consuming and is not scalable. The second approach is to rely on one of CMO's data exporting mechanism. CMO's Event Export can perform automatic data export, but the types of features are limited to several pre-determined categories, e.g. unit positions, sensor detection attempts, fuel consumption, etc. One could conceivably use this feature to write data out to a db3 or csv format and then stream the data to the environment. However, the limited feature categories hinder this approach from being perfect.
For our purposes, the best approach was to rely on the Lua command ScenEdit_ExportScenarioToXML, which exports the entire scenario to an XML file. This file contains information about everything that is happening in the scenario at the time the function is invoked. In fact, one can recreate the scenario in that moment by calling the function ScenEdit_ImportScenarioFromXML.

The XML file is organized into a tree rooted at the scenario node, which contains no information (see Figure 4). One level below the root, the first few nodes contain "meta" information about the scenario, to include the title, description, current time, duration, etc. At this level, there are more important subtrees like sides and activeunits. The sides subtree contains information about each side, and each side has a subtree rooted at the sides node. Side information include the side's name, doctrine, reference points, contacts, and missions. Each of these features contain their own subtrees. The activeunits subtree contains information about units in the game. Each subtree within the activeunits subtree is rooted at a node that specifies its type. For example, if we had an aircraft in the game, then we can expect to see the subtree activeunits > aircraft > {id, name, …}. Each unit subtree contains information about the unit's name, type, position, as well as its sensors, mounts, and weapons. Then, within PyCMO, features.py handles the work of extracting this information from the XML file and loading them into a data format that can be used by agents.
Since XML files can get unwieldy, I relied on Martin Blech's xmltodict library to convert XML files into JSON-like (dictionary) objects. After converting the scenario XML into a dictionary, features.py parses the dictionary and packages all the relevant observations into a class called Features, which contains named tuples that collect information about the game's metadata and a side's metadata, units, mounts, loadouts, weapons, and contacts (you can read about the list of attributes in PyCMO's documentation). Features takes as input 2 required arguments: xml and player_side. xml is the path to the XML file generated from the game that contains information at a particular timestep. player_side is a string that defines the agent's side in the game. Features is an object that is unique to a particular side, so it will not hold information about other sides that a side would not usually know.
There were and continues to be several challenges to parsing data from the XML file. First, each XML is unique to each scenario. Although there are overarching similarities between scenarios (e.g. one can always expect to find metadata about the scenario), certain scenarios will contain data fields that do not appear in other scenarios. For example, a scenario with ships will have ship entries, while a scenario without any ships will not. This is all to say that there was a lot of error checking that had to be done during parsing. I originally claimed that outputting data using the io feature would be less efficient because the Lua script would have to be tailored for each scenario. However, this is not completely true as there might also be future modifications (extra work) that need to be made to features.py to account for some unique scenario. I suppose it all comes down to preference. Do you want to format the data first and then output it (writing a script in Lua and then using io), or do you want to output the data first and then format it (using ScenEdit_ExportScenarioToXML and xmltodict)?
The second difficulty with parsing observations is directly related to the development of agents. The purpose of Features is to encapsulate all the useful information about a scenario and discard the rest. However, useful does not imply relevant. Thus, the designer must still pair down Features quite a bit and tailor it for their agent. For example, if you were just training an agent to navigate an aircraft through a gauntlet of SAMs, you probably only need to know information about the aircraft and the SAMs. However, Features should have done most of the heavy lifting so that this process should be easier. A challenge that arises when one considers the possibility of employing deep learning agents in CMO is that Features is not static. There are two senses in which Features is not static. First, Features is not static because it changes depending on the scenario (as we alluded to earlier). Thus, we would need different agents for different scenarios, which precludes the possibility of one general agent that can solve a gauntlet of scenarios. Second, Features is not static within a scenario if there are major changes in the scenario. For example, if a unit that was initially present in the scenario dies halfway through, Features might no longer contain information about that unit. Thus, agent developers must be mindful of how to handle "missing input" when working with Features. If the agent is represented by a neural network with the input nodes being features from Features, we must know how to deal with the situation in which several input nodes receive no information because a unit gets destroyed. A thought on how to deal with this is to embed the feature/state space into common embedding, like how language models embed text using word embeddings. This would lead to a more general representation of the state space that might be more flexible to deep learning agents.
Actions
Taking inspiration from PySC2, PyCMO's actions.py defines the action space as a collection of Lua functions and AvailableFunctions, a class which contains actions that are available only at a particular timestep. During each timestep, AvailableFunctions must be initialized with a Features object so that a list of valid actions can be generated. Since the majority of the development was spent on features.py, I did not get very far with actions.py. Consequently, there are currently only eight defined actions. However, the actions are expressive enough to launch an aircraft from a base, set its course, attack a contact, refuel the aircraft, and command it to return to base.
Like PySC2, actions.py encapsulates each primitive action (represented by a Lua script) in a Python function. For example, the function set_unit_course takes as input the parameters side, aircraft_name, latitude, and longitude, and returns the Lua script string:
--scriptTool_EmulateNoConsole(true) ScenEdit_SetUnit({side = '{side}', name = '{aircraft_name}', course = {longitude = '{longitude}', latitude = '{latitude}', TypeOf = 'ManualPlottedCourseWaypoint'}})The first two lines tell CMO that we want to run the following script in no console mode. Running scripts through CMO's TCP/IP port can be finicky and I found that the first two lines were often required. The third line is the script that gets executed, where the parameters side, aircraft_name, latitude, and longitude would have been replaced by the actual parameters passed to the function set_unit_course.
A function is represented by the Function named tuple. A Function is defined by a unique ID, a unique name, its corresponding Python definition, the valid arguments (dependent on the timestep), and the types of valid arguments. For example, within actions.py, the action of setting a unit's course has ID 2, the name "set_unit_course", the set_unit_course Python function, and four lists of valid arguments. The valid arguments for each function are defined in the list VALID_FUNCTION_ARGS. The entry for "set_unit_course" is a list of length four. The first entry in the list is a list of the sides that are present in the game and corresponds to the first argument in the set_unit_course Python function. The second entry in the list is a list of unit names and corresponds to the second argument in the set_unit_course Python function. The third and fourth entries in the list define valid ranges for longitudes and latitudes. An agent should sample (or preferably decide) latitude and longitude values that are within this range. The first and second arguments' type is EnumChoice, which stands for enumerated choice. This essentially means that the first and second arguments' domain is a collection of objects from which one choice can be chosen (e.g. the side name). In contrast, the third and fourth arguments' type is Range, which means that the third and fourth arguments need to be a value (usually real-valued) within the specified range. Whereas ARG_TYPES can be useful towards deciding the values with which an argument should take, VALID_FUNCTION_ARGS enumerates the list of valid arguments. Then, agents can either randomly sample from an AvailableFunctions object during gameplay or use it to decide on an action. The most basic example of how actions.py is used is an agent taking random actions. It can first sample from the list of valid functions for a Function. Then, it will just need to check the VALID_FUNCTION_ARGS list and sample arguments from there accordingly.
Environment
Having completed our discussion on protocol.py, features.py and actions.py, we are ready to discuss how cmo_env.py ties everything together into an RL environment. Like PySC2, PyCMO captures data emitted by the environment at each timestep in a TimeStep class, where each TimeStep has a unique ID, a step type, and the associated reward and observation (in the form of a Features object. A TimeStep is what an agent receives from the environment. The class CMOEnv represents the wrapper that extracts observations from and sends actions to the game. During the initialization of the environment, it is important to specify a step size in terms of hours, minutes, and seconds. This determines the duration of a step, and must be set accordingly to the learning agent. The most important function in cmo_env.py is CMOEnv::step, which sends an action to the game and returns a TimeStep object. At the time I was developing the project, the Lua function VP_RunForTimeAndHalt looked like a promising step mechanism. The function is currently not present in the CMO documentation (maybe the developers removed it because it was so buggy), but it was supposed to run the scenario for a set duration and then pause. The idea of CMOEnv::step was to send the agent's action to the game, run the scenario for a certain duration, and then record the resulting state after the duration had passed. However, since VP_RunForTimeAndHalt did not work (it would run the scenario but would not pause it after the set duration), I had to implement a hack. Basically, after sending the agent's action to the game, we continuously poll the game and check the time. If the correct period of time has passed, we can pause the game and output the XML. There should be a function for this, but upon reviewing the code and the documentation, I do not see this being implemented, which probably means that the pause command in Lua was also buggy. Assuming that we can pause the game, we then pass the most current XML file to a Features object and save the result in an observation variable. At the time I was developing CMO, I chose a simple reward scheme where the reward was represented by the side's current score. Obviously, more robust and sophisticated schemes can be constructed. CMOEnv contains a few other helpful functions, such as resetting the environment and returning the first TimeStep, checking whether the scenario has ended, restarting the Client in case there were connection issues with the Server, and determining the list of valid functions given an observation.
One final thing we can remark about the project is run_loop.py, which properly defines the RL loop shown in Figure 2. The run_loop represents an RL loop of interaction between an agent and an environment. The function takes as input the player's side, the step size, the agent, the maximum number of steps, the type of server to initialize, and the scenario file corresponding to the scenario. run_loop works with an already-running instance of CMO, or it can also initialize a Server instance on a separate thread. During initialization, run_loop sets the first step ID to 0, and calls CMOEnv::reset to reset the environment. Then, run_loop also keeps track of the current time. The main loop will run until the game ends or the number of steps exceeds the maximum allotted steps. Within the main loop, we call CMOEnv::action_spec to get a list of valid actions at the current timestep. Then, the loop calls on the agent to take an action. We shall discuss agents in the next section, but every agent should have a get_action function that takes as input the current observation and a set of valid actions and return an action in the form of a properly formatted Lua script. Then, run_loop increments the step ID by 1 and calls on the environment to step forwards after executing the agent's action.
Agents
I originally had four agents planned, and one of my biggest regrets is not completing them in time for the competition's submission deadline. Nevertheless, the building of a sophisticated agent represents an exciting area of work to tackle in the future. As of this writing, the only agent that I finished developing was the RandomAgent, which randomly samples actions from the list of valid actions. This agent is dumb in the sense that it does not consider any observations. One level above the RandomAgent in terms of sophistication are the RuleBasedAgent and ScriptedAgent. The RuleBasedAgent is still in development, and it needs to be tailored to each scenario. The one rule-based agent I finished was for the Wooden Leg scenario, and it was designed to launch F-15 fighters to strike some targets. These agents are more sophisticated than the random agent because they use observations from the environment to make decisions, albeit in a very static way.
As we alluded to earlier in the blog post, the dream was to replicate AlphaStar in CMO. Thus, the goal is to develop a deep learning agent for CMO. There are challenges involved with this task due to the complexity of CMO. First, given that our agent will probably incorporate some type of neural network, we must solve the problem of the non-standard feature space. The feature space, as it is currently captured by the Features object, is subject to changes within a scenario. Thus, learning with this object might not be stable. An idea we alluded to earlier was to develop a common embedding for all scenarios. To go into a bit more detail, an embedding is a good idea because there are a lot of different types of information captured by a Features object. For example, given a complex scenario, the Features object will contain information about aircrafts, ships, weapons, loadouts, contacts, and the data types will be both numerical and textual. As a result, embeddings seem to be a good idea to deal with this “mixed data.” Another challenge with developing an RL agent is the design of rewards. CMO scenarios can get very complicated, and to design rewards in such a way that can lead the agent to solve the scenario's goal(s) is a big challenge to consider. Finally, one must also consider whether the action space as it is currently defined by actions.py is expressive enough for an agent to make or exceed human-level decisions. We would probably need to revisit actions.py to answer this question.
Conclusions
I initially thought it was going to be easy to write this blog post, but it took me around two weeks of writing (and procrastinating) to finish everything. The writing was hard because I had to review a lot of work that I did more than a year ago, and to remind myself of my thoughts and feelings at the time. Moving forward, I should write blog posts when the memory of the project is still fresh in my mind. Nevertheless, the writing of this blog post should not have been hard because this project is by no means finished. There is still a lot of work to be done, and apparently, a lot of people waiting for it to be done. As of this writing, the PyCMO repository has 16 stars and 11 forks, which makes it one of my all-time most popular repositories. The only thing stopping me from doing more with the project is that I no longer have access to a Professional version of the game. However, if there is a will, there will be a way. Hopefully, I can carve out some more time to refine PyCMO and to work on the agents. In conversation with other people interested in the work I am doing, I have also come across the idea of porting PyCMO into an OpenAI Gym environment. I think that would be a very good idea.
© 2023 Minh Hua